
Web ページの HTML の構造を利用して、XPath (XML Path Language)を利用することでツリー構造となっているXML/HTMLドキュメントから要素や属性値などを取得することができます。今回はブラウザ上で簡単に確認することができるアドインを紹介します。
Xpath とは
ChatGPT に聞いてみました。
XPathとは、XML形式の文書から、特定の部分を指定して抽出するための簡潔な構文 (言語)です。HTML形式の文書にも対応します。CSSではセレクタを使ってHTML文書内の特定の部分を抽出しますが、XPathはより簡潔かつ柔軟に指定ができるとされています。
便利ですね、ChatGPT は。Web サイトの HTML のデータはページのテンプレートごとに同じ構造で表示されるはずです。これを利用して、ページの中から要素を取得することができます。
開発者ツールの活用
一般的に提供されているブラウザには、開発者ツールが追加されています。このツールを利用することで、データが表示されているパスを取得することができます。
例えば、XM Cloud - Sitecore Content Hub コネクタを有効にするのページで開発者ツールを起動すると以下のような画面になります。

右側にあるツールの画面の中で、Select an element in the page to inspect it のアイコンをクリックすることで、ページを指定すると該当するタグを選択することができます。
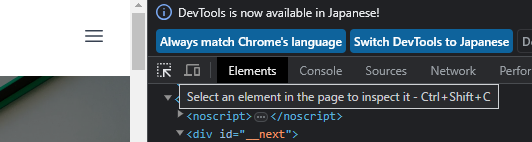
ブログページの日付を表示されている項目にマウスカーソルを合わせると、下図のようにソースコードもハイライトされます。
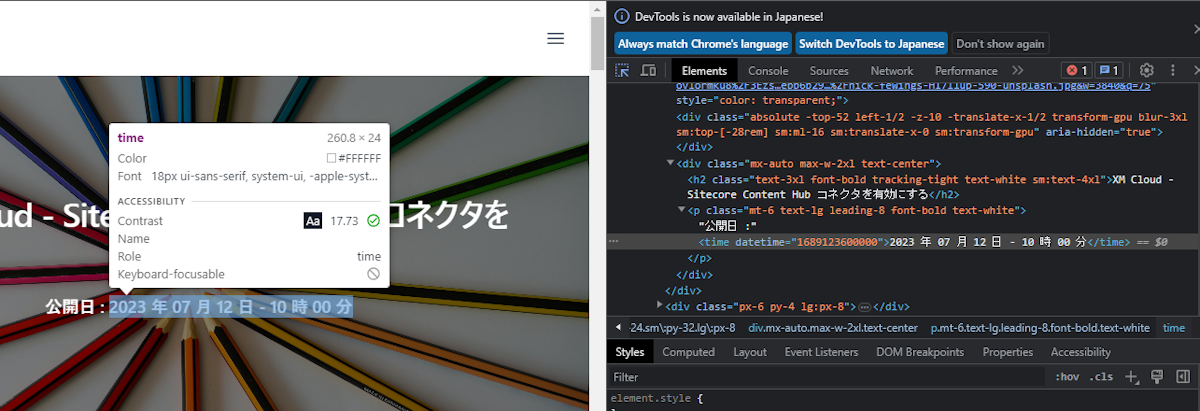
該当するソースコードを右クリックして、Copy のメニューからコピーをする方法をいくつか選択することができます。ここで Copy XPath を選択してください。
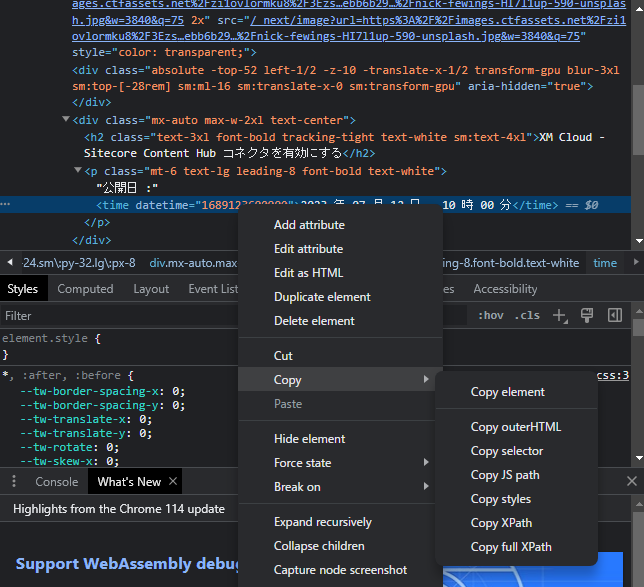
以下のような Xpath を取得することができます。
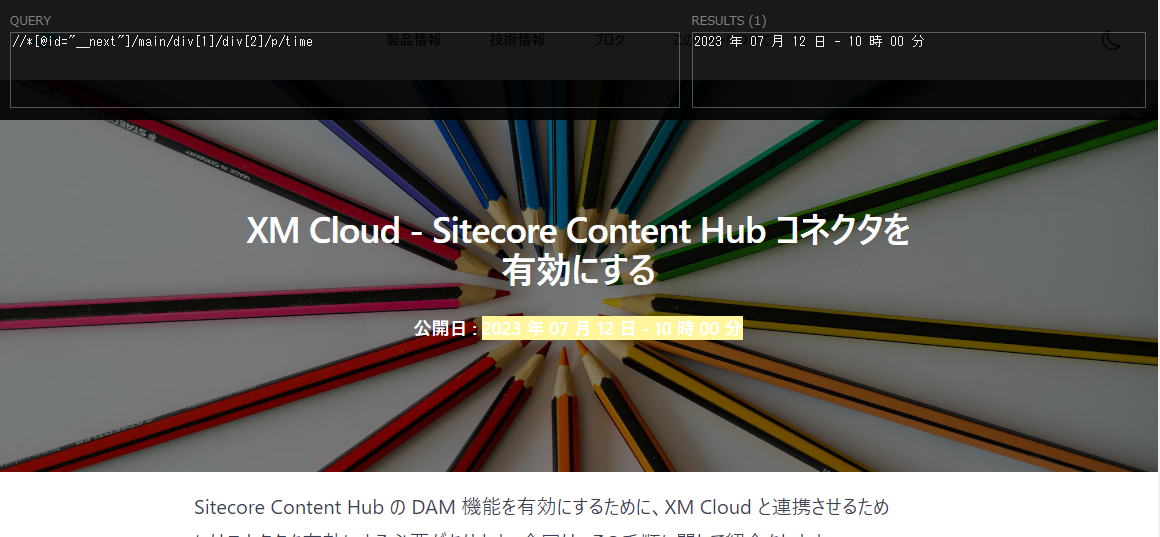
//*[@id="__next"]/main/div[1]/div[2]/p/timeブラウザで確認をする
表示しているページに対して、XPath を利用してデータが正しく取得できるかどうかを確認することができるアドインはいろいろとありますが、今回はXpath Helper を紹介します。
Xpath Helper ( Chrome / Edge で利用可能)
このアドインをオンにすると、ブラウザの上に2つのテキストボックスが表示されます。
1つ前の手順で取得した XPath を左側のテキストボックスに入力すると、結果を右側のテキストボックスに表示されます。
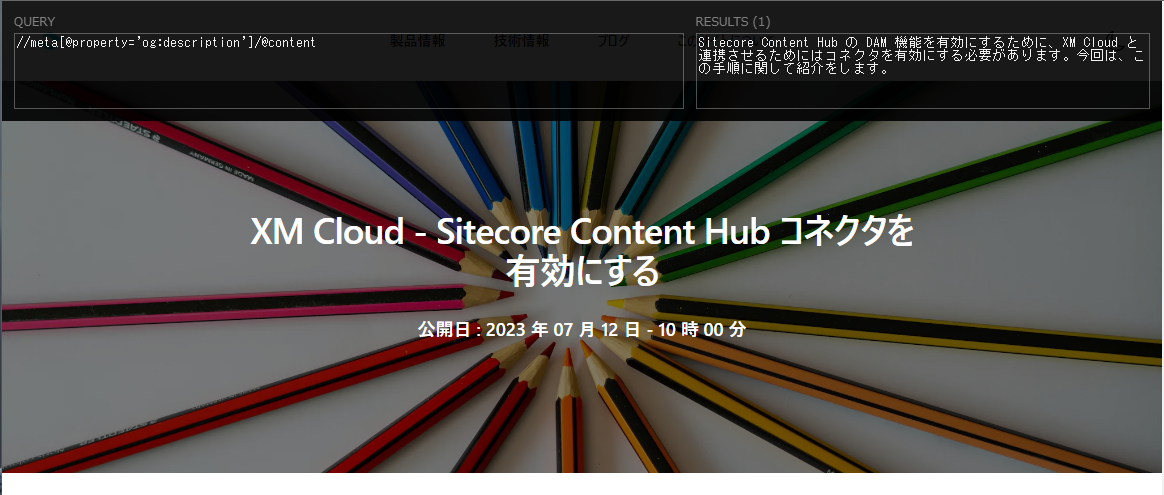
実際にページに表示されていない Meta データを確認する場合にも利用できます。例えば、以下のコードを利用してください。
//meta[@property='og:description']/@content結果は以下のように表示されます。
このツールを使うことで、Web ページのデータを取得して活用することができます。
まとめ
今回は Xpath Finder のアドインを利用して、Web ページのデータを取得する方法を紹介しました。ページの構造を確認する簡単な手順は開発者ツールがあるだけでも十分ですが、このツールも便利なので平行して今後はブログ記事でも紹介していきます。